
Mastering LLaMA2: Setup, Use, and Integration in Various Environments
Explore the versatile world of Meta AI's LLaMA2 – from setup to text generation, translation, and more, and unlock AI's potential in business.


In our last foray into the world of artificial intelligence, we delved into the fascinating intricacies of Meta AI's LLaMA2, a behemoth in the realm of large language models. We explored its unique architectural elements — from its multilingual prowess, handling an astronomical 2 trillion tokens, to advanced features like Grouped Query Attention and Rotary Positional Embedding. Our journey illuminated how LLaMA2, with its open-source nature and ethical AI development, is not just a tool but a testament to the future of AI and NLP.
But understanding its architecture is just the beginning. The true power of LLaMA2 lies in its application, in bringing this AI marvel to life in diverse environments. This article marks the next chapter in our exploration — a practical guide on setting up and using LLaMA2. Whether you're navigating the realms of Google Colab, configuring it on local machines, or integrating it into various applications, we're here to guide you through each step. Prepare to unlock the full potential of LLaMA2, as we embark on a journey from installation to implementation, harnessing the prowess of this AI masterpiece in the real world.
Exploring AI's Future: Unveil the advanced capabilities of LLaMA2 and its impact on the evolving landscape of artificial intelligence.
Practical Applications: Learn how to seamlessly integrate LLaMA2 into various environments, a valuable skill set for AI enthusiasts and professionals alike.
Cross-Language Understanding and Global Reach: With its proficiency in handling 20 languages, LLaMA2 is not just a language model but a polyglot powerhouse.
Starting with LLaMA2
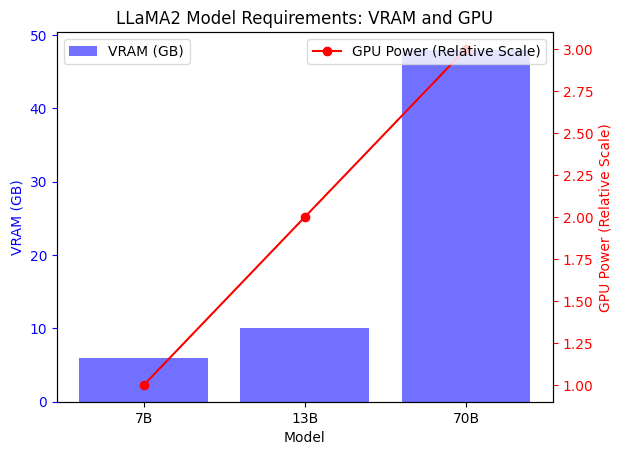
Imagine LLaMA2 models as different breeds of a mystical creature, each with its own unique strength and appetite. The 7B, 13B, and 70B variants represent their power - the higher the number, the more powerful (and resource-hungry) they are. Selecting one is akin to choosing a mount for your AI journey; the 7B is agile and less demanding, while the 70B is a powerhouse, requiring substantial VRAM and a robust GPU to tame its capabilities. The graph below illustrates the VRAM and GPU needs of each LLaMA2 variant. The blue bars show VRAM in GB, essential for memory capacity — 6GB for 7B, rising to 48GB for 70B. The red line represents the "Relative GPU Power," a scale of compatibility and efficiency, where 1 equates to RTX 3060, scaling up to 3 for RTX 3090.
In the land of LLaMA2, there are two distinct species: the Base and Chat models. The Base model is like a well-rounded scholar, versed in a wide range of knowledge. One can use it for a variety of tasks like machine translation, question answering, etc. The Chat model, however, is a refined version of the base, finely tuned to be a seasoned conversationalist. It excels in the nuanced art of dialogue, perfect for tasks requiring sophisticated interaction, like chatbots or virtual assistants. Your choice depends on your quest - broad AI applications or specialized conversational tasks.
Setting the environment
Setting up the environment for LLaMA2 requires some crucial steps. First, we need to install key libraries: transformers and accelerate. These libraries are the backbone, providing the necessary tools and functions to interact with the model effectively. Install them via pip commands.
pip install transformers
pip install accelerate
Additionally, accessing LLaMA2 models hosted on Hugging Face necessitates logging into the Hugging Face CLI. This step is essential as it authenticates your access, ensuring a secure and seamless connection to the LLaMA2 models.
Utilizing Base LLaMA2 Model for Diverse Language Tasks
With the environment set, we're now ready to embark on a journey of text generation, translation, and question-answering. Let's start by gathering our tools:
from transformers import AutoTokenizer, AutoModelForCausalLMLet us break down these two imports. Text is complex; computers speak in binary, and therefore, they need a translator that can translate text from human-readable format to its binary format - this is where Tokenizer comes into the picture. Imagine it as a savvy linguist, adept at decoding the intricacies of human language and converting them into a digital dialect, a sort of binary Esperanto, that computers can understand. This process, known as tokenization, is the bridge between our world of words and their realm of ones and zeros. You can think of it as a skilled translator, adept at converting human language into a format that the AI models can understand. Tokenization is the process of transforming words and sentences into a series of tokens - a language that AI can comprehend. It's the first, crucial step in turning our human thoughts into insights a machine can process and respond to.
Each language model, much like unique cultures across our world, has its specific linguistic idiosyncrasies. And therefore, each requires its own tokenizer. Enter the AutoTokenizer class from Hugging Face. This intelligent tool automatically selects the appropriate tokenizer for the specific LLM model we're using. It ensures that our text is precisely segmented into tokens in a way that's compatible with the model's internal workings. By handling this intricate translation, AutoTokenizer enables us to communicate seamlessly with LLMs, setting the stage for sophisticated language tasks like text generation, translation, and question-answering.
Now, in this post, we are working with LLaMA2, which is an autoregressive model; therefore, we imported the AutoModelForCausalLM class. This class is tailored for models that generate text sequentially, predicting each token based on the previous ones, just like a storyteller weaving a tale word by word.
The Hugging Face library offers a treasure trove of LLaMA2 variants, including both PyTorch-compatible versions and those optimized in the Hugging Face-exclusive safetensor format. For our adventure, we've chosen the 7b version from meta-ai, renowned for its balance of power and efficiency, and available in the user-friendly safetensor format:
model_name = ‘meta-ai/llama2-7b-hf’
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
In this snippet, model_name is our map to the right treasure. The AutoTokenizer.from_pretrained function summons the model's translator, ensuring our text is perfectly understood by LLaMA2. Then, AutoModelForCausalLM.from_pretrained brings the model itself to life, ready to generate text with the wisdom of its 7 billion parameters. This setup is our gateway to exploring the linguistic capabilities of LLaMA2, where each token generated is a step further into the realm of AI-driven language understanding.
Having established the groundwork with our AutoTokenizer and AutoModelForCausalLM classes, we're well-equipped to harness the linguistic prowess of LLaMA2. This setup, where we meticulously select our model and its accompanying tokenizer, offers us detailed control over our language tasks, be it text generation, translation, or question-answering.
However, for those seeking a more streamlined approach, the Hugging Face library presents us with another, more direct path: the pipeline function. This function acts as a comprehensive tool, bundling together the model and tokenizer, and simplifying the process of employing the model for different tasks. To use pipeline, you just need to give the model_name, the task that you want to perform, for example, ‘text-generation’, ‘question-answering’ or even translation.
from transformers import pipeline
llm = pipeline(<specify-task>, model=model_name)
With this pipeline, using LLMs becomes almost effortless. You simply provide a prompt, and the pipeline takes care of the rest – from processing your input with the right tokenizer to invoking the model to generate a response. It's like having an all-in-one tool that encapsulates the complex steps into a single, intuitive command.
Whether you prefer the detailed approach of setting up each component or the convenience of the pipeline, LLaMA2 stands ready to transform your textual inputs into meaningful, contextually rich outputs. Each method opens a different door to the same vast landscape of AI-driven language understanding, inviting you to explore and experiment with this cutting-edge technology.
Text Generation using LLaMA2
Text generation is a fascinating aspect of AI, where we enable machines to create human-like text. It's akin to teaching a computer to mimic human creativity, generating everything from stories and poems to realistic dialogues and answers. In essence, we're giving AI the tools to craft sentences, paragraphs, or even entire articles based on given prompts or starting points.
To harness the power of LLaMA2 for text generation, we employ the Hugging Face pipeline; here is the code:
from transformers import pipeline
import torch
model_name = "meta-llama/Llama-2-7b-hf"
text_generator = pipeline('text-generation', model=model_name, device_map="auto", torch_dtype=torch.float16)
Let's break down the code and understand each component:
- `pipeline('text-generation', ...)` initializes a pipeline for text generation. This setup tells the pipeline we're focusing on generating text.
- model=model_name tells the pipeline which specific model to use, ensuring it aligns with our task.
- device_map="auto" allows the pipeline to automatically choose the best device (CPU or GPU) available. This ensures optimal performance without manually specifying the device.
- torch_dtype=torch.float16 sets the data type to 16-bit floating-point (half-precision). This reduces memory usage and can speed up model inference, especially on compatible hardware. It's a balance between performance and precision.
Now, let's put our pipeline into action to generate text from a given prompt. For this demonstration, we'll explore the theme of 'Artificial general intelligence.' Here's how we set it up:
prompt = 'Artificial general intelligence is'
sequences = text_generator(
prompt,
do_sample=True,
top_k=50,
temperature=0.99,
top_p=0.92,
repetition_penalty=1.2,
num_return_sequences=1,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
In this script, the prompt variable ignites the spark of creation, serving as the starting point for our text generation. The parameters within the text_generator function are knobs and dials, adjusting the model's approach to generating text:
- do_sample=True: This enables random sampling, allowing for creative and varied text generation.
- top_k=50: Restricts our model to consider only the top 50 tokens at each step, balancing creativity and coherence.
- temperature=0.99: Sets the 'creativity thermostat.' A higher temperature increases randomness, pushing the boundaries of conventional responses.
- top_p=0.92: Implements nucleus sampling, where the model focuses on a smaller set of high-probability options, enhancing relevance and variety.
- repetition_penalty=1.2: Applies a subtle nudge to the model to avoid repetition, encouraging novel sentence structures.
- num_return_sequences=1: Determines the number of different responses the model generates.
- max_length=100: Caps the length of the generated text, ensuring concise and focused output.
Feel free to play around with these parameters. Adjusting them can significantly alter the style and content of the generated text like a chef tweaking a recipe to perfection. Experimentation is key – each change can lead to new and exciting discoveries in the realm of AI-generated text.
Leveraging LLaMA2 for Translation Tasks
LLaMA2, primarily an autoregressive language model, shines in text generation and conversational tasks. While not explicitly designed for translation, its training across 20 languages equips it with a unique polyglot ability. This capability can be harnessed for translation through clever prompting, essentially guiding the model to perform a task it wasn't specifically fine-tuned for. By structuring our input in a specific way, we can nudge the model to translate text from one language to another. Here’s how we set up the prompt for our translation task:
sequences = text_generator(
'"I enjoy reading books" can be spoken in french as: ',
do_sample=True,
top_k=50,
temperature=0.99,
top_p=0.92,
repetition_penalty=1.2,
num_return_sequences=1,
max_length=30,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")In this script, we carefully craft the prompt to indicate our translation intent. The phrase "I enjoy reading books" can be spoken in French as: informs LLaMA2 of our desired output.
In a similar vein to our translation task, we can ingeniously leverage the LLaMA2 base model for question-answering by employing clever prompting techniques. By structuring our input to guide the model, we can coax it into providing answers to specific questions. Consider this example:
question = "What is the capital of France?"
context = "The capital of France is"
prompt = f"{context} {question} The answer is:"
In this setup, the context string sets the stage by providing a relevant lead-in. The question is then integrated seamlessly, followed by an anticipatory cue, 'The answer is:', which signals to the model that a response is expected.
Final words
LLaMA2 from Meta AI represents a significant advancement in the field of large language models, showcasing remarkable capabilities in multilingual processing and advanced AI features. This post has demonstrated the ease of setting up and integrating LLaMA2 across various platforms, highlighting its flexibility and power in diverse applications. From text generation to translation and question-answering, LLaMA2 proves to be a versatile and accessible tool, paving the way for future innovations in AI and natural language processing.
Contributors
Amita Kapoor: Author, Research & Code Development
Narotam Singh: Copy Editor, Design & Digital Management