
Elevating Large Language Models with Retrieval-Augmented Generation
Dive deep into Retrieval-Augmented Generation (RAG) models. Understand their architecture, implementation with LlamaIndex, and diverse applications.


Picture this: a computer that can write like a person, but with the superpower of reading through a whole library in seconds to give the best answers possible. Welcome to the world of Retrieval-Augmented Generation or RAG for short.
RAG models stand out for their ability to generate responses that are not just coherent but also deeply rooted in specific, factual information, thanks to their unique architecture that blends generative and retrieval capabilities. RAG can produce insightful, accurate, and contextually rich text by tapping into a wealth of embedded knowledge from various sources, such as a snapshot of Wikipedia and other substantial data. This is particularly impactful in the realm of Question Answering (QA), where the model can sift through its vast internal knowledge repository to formulate answers that are not merely coherent but also informatively exhaustive and accurate. Particularly in the domain of QA, RAG truly exemplifies its prowess, merging retrieval and generation into a seamless, informative dialogue
In this journey through the labyrinth of RAG and its implementations, we will unravel the intricate tapestry of various frameworks, critically examining each to illuminate their strengths and potential pitfalls. But the intrigue doesn’t end there.
We’ll also dip our toes into the practical world of implementing RAG, offering you a hands-on experience through an engaging code example with LlamaIndex, applied to the data of our choice.
Whether you're an AI veteran or a curious newcomer, fasten your seatbelt as we embark on this enlightening voyage through the depths of Retrieval-Augmented Generation, ensuring you’re armed with the knowledge to select and implement the RAG framework that will elevate your work to new heights.
Peeling Back the Layers of RAG
Large Language Models (LLMs), despite being the cool kids in the Natural Language Processing (NLP) block, find themselves in a bit of a pickle when it comes to grasping and navigating through the mazes of context. Imagine having a super-smart friend who’s read a gazillion books but can only recall stuff from them and nothing newer – that’s LLM for you! Here, our star, RAG, enters and gleams, addressing LLMs' inherent contextual and memory limitations. It brings to the table an ability to not merely communicate but forge connections, teasing out nuanced threads from user queries, and intertwining them with a tapestry of relevant, embedded knowledge. RAG thus doesn’t merely provide answers; it crafts narratives that are as deeply rooted in contextual understanding as they are in factual accuracy.
Let’s take a closer peek at these three musketeers - Retriever, Argumentation, and Generator - each playing a pivotal role in elevating RAG’s prowess.
- The Retriever: The Information Sift-and-Seek Maestro: Imagine having a gargantuan library with innumerable books, articles, and snippets of information. The Retriever acts like an astute librarian, meticulously sifting through this colossal data repository and cherry-picking pieces of information that align splendidly with the user’s query. It doesn’t just seek; it discerningly selects, ensuring only the most relevant data chunks are brought into the limelight.
- The Argumentation: The Harmonizing Conductor: Once the Retriever handpicks the relevant data nuggets, the Argumentation steps in like a skilled conductor, harmonising the originally posed query and the freshly retrieved information, crafting a cohesive, single input. It's like mixing the perfect cocktail of user intent and external knowledge, ensuring the ensuing generation is relevant and richly informative.
- The Generator: The Artful Text Composer: Meet the Generator, typically a robust Large Language Model like GPT-3, which artfully composes the final text response. It takes the harmonised input, an amalgam of the user query and retrieved information, and weaves it into a text that’s not just a mere answer but a comprehensive, contextually rich dialogue. It doesn’t just respond; it converses, ensuring the user is engaged in a meaningful, informative exchange.
In this triumphant trilogy, RAG crafts responses that are not merely regurgitating memorised data but a finely tuned blend of retained knowledge and freshly retrieved information.
Choosing the right Framework for RAG
Diving into the RAG framework world? Buckle up, for you're in for a delightful ride! Here's how to swerve and pivot to make the best pick:
- Ease of Use: Dive into a pool, not an ocean. Choose a framework where both newbies and pros feel right at home, transforming complex machine magic into everyday sorcery.
- Flexibility: Like your favourite yoga pose, your RAG should bend and twist to match your every whim. Make sure it meets your unique demands, allowing for those creative tweaks and twirls.
- Performance: Got data? Loads of it? Your chosen framework should dance through it gracefully, handling the sprints and the marathons effortlessly.
- Scalability: Dream big! Your framework should be ready to party, whether it's a cosy get-together or a massive gala.
- Support: Be in a crowd that cheers you on. Pick a framework with a vibrant community and devoted code wizards, ensuring you're never alone in your RAG journey.
But hey, keep an eye out for some golden features: various document retrievers, nifty passage ranking models, eloquent text generators, integrated knowledge bases, and the art of prompt engineering to elevate your RAG game.
Now, onto the million-dollar question: Which framework should wear your crown? Take a glance at our charted trio below:
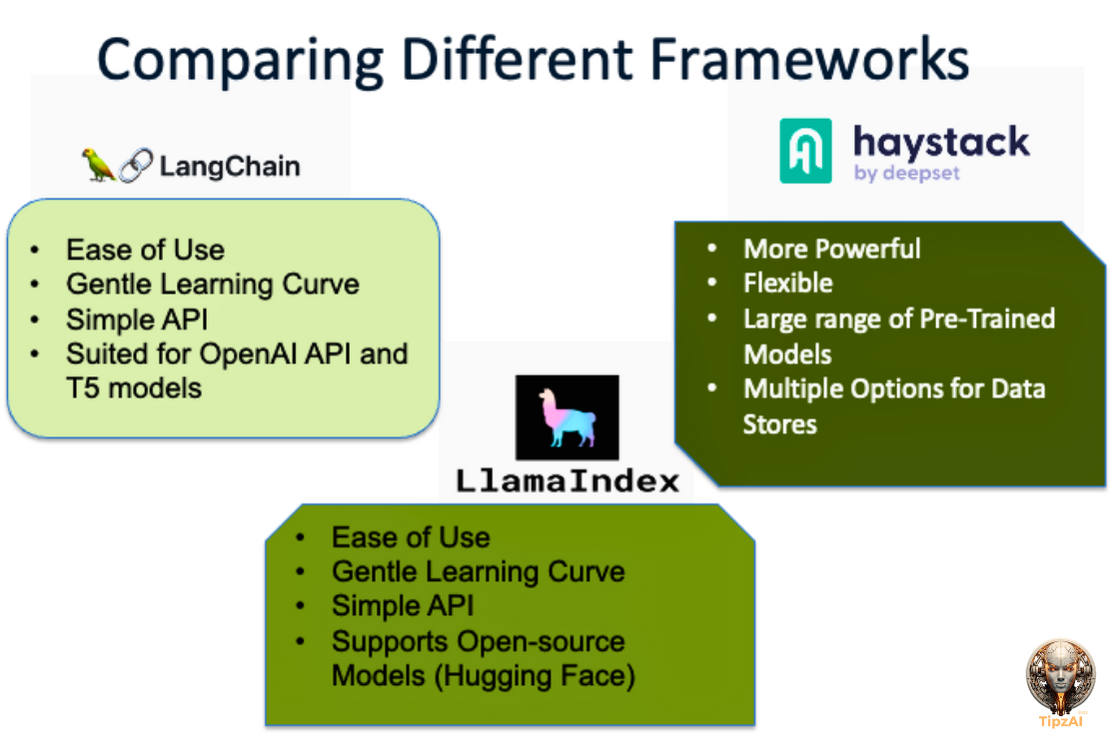
Note: These names (LangChain, Haystack, and LlamaIndex) are used here for identification purposes only and may be trademarks or registered trademarks of their respective companies. The mention of these trademarks does not imply any affiliation with or endorsement by their respective holders.
If you're just starting, LangChain is your best bet. For those vibing with open-source, LlamaIndex is the way. And for the veterans who've seen it all in the RAG domain, Haystack's your power play. Speaking from my journey handling multiple RAG projects! 🚀📚🧭.
Taking the RAG Plunge with LlamaIndex
Diving into RAG with LlamaIndex? 🦙 Gear up! First off, embeddings: Think of them as texts translated into the secret code of computers. My pick is the slick `BAAI/bge-small-en` model by the Beijing A-listers of AI, BAAI. Why? Because of its mastery in bidirectional autoencodings!
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en")
Generator? Go for the Llama-2-13B-chat-GGUF*. It's like the Beyoncé of language models: iconic, vast, and flawless for QAs!
*Note: Please be aware that the utilization of this model is subject to the terms outlined in the Meta license. For access to the model's weights and tokenizer, you are required to first agree to License on the official website before proceeding with the access request on this platform.
model_url = "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q4_0.gguf"
generator = LlamaCPP( model_url=model_url,temperature=0.1,max_new_tokens=256,
context_window=3800,generate_kwargs={},model_kwargs={"n_gpu_layers": 1},verbose=True,)
Blend 'em in the LlamaIndex ServiceContext cocktail: the ultimate mixer for your query pipelines!
service_context = ServiceContext.from_defaults(llm=generator, embed_model=embed_model)Database? Roll out the red carpet for Supabase-powered Postgres! 🚀
url: str = "<your_database_url>"
key: str = "<your_key>"
supabase: Client = create_client(url, key)
db_name = "postgres"
host = "<your_host_address>"
password = "<your_password>"
user = "<your_user>"
port = 5432Got your data? Let's slice'n dice it:
PyMuPDFReader = download_loader("PyMuPDFReader")
loader = PyMuPDFReader()
documents = loader.load_data(file_path="<path_to_your_pdf>")
text_splitter = SentenceSplitter(chunk_size=1024)
text_chunks, doc_idxs = [], []
for doc_idx, doc in enumerate(documents):
cur_text_chunks = text_splitter.split_text(doc.text)
text_chunks.extend(cur_text_chunks)
doc_idxs.extend([doc_idx] * len(cur_text_chunks))To enable semantic search, we use TextNode:
nodes = []
for idx, text_chunk in enumerate(text_chunks):
node = TextNode(
text=text_chunk,
)
src_doc = documents[doc_idxs[idx]]
node.metadata = src_doc.metadata
nodes.append(node)
Next, give 'em the embedding treatment:
for node in nodes:
node_embedding = embed_model.get_text_embedding(node.get_content(metadata_mode="all"))
node.embedding = node_embedding
Enter PGVectorStore: Imagine a librarian with superpowers, sorting and finding book-like vectors with ease. That's PGVectorStore for your docs!
vector_store = PGVectorStore.from_params(
database=db_name,
host=host,
password=password,
port=port,
user=user,
table_name="My_data",
embed_dim=384,
)
Load up that database!
vector_store.add(nodes)All set? Let’s get that retriever:
class VectorDBRetriever(BaseRetriever):
"""Retriever over a postgres vector store."""
def __init__(
self,
vector_store: PGVectorStore,
embed_model: Any,
query_mode: str = "default",
similarity_top_k: int = 2,
) -> None:
"""Init params."""
self._vector_store = vector_store
self._embed_model = embed_model
self._query_mode = query_mode
self._similarity_top_k = similarity_top_k
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""Retrieve."""
query_embedding = embed_model.get_query_embedding(query_str)
vector_store_query = VectorStoreQuery(
query_embedding=query_embedding,
similarity_top_k=self._similarity_top_k,
mode=self._query_mode,
)
query_result = vector_store.query(vector_store_query)
nodes_with_scores = []
for index, node in enumerate(query_result.nodes):
score: Optional[float] = None
if query_result.similarities is not None:
score = query_result.similarities[index]
nodes_with_scores.append(NodeWithScore(node=node, score=score))
return nodes_with_scores
retriever = VectorDBRetriever(
vector_store, embed_model, query_mode="default", similarity_top_k=2
)Let's assemble our query powerhouse:
query_engine = RetrieverQueryEngine.from_args(
retriever, service_context=service_context
)
Now for any query, you take the query text, and, give to the query engine, and voila we have the answers:
query_str = "What are paleorecords and how do they provide insights into climate change effects on marine life?"
response = query_engine.query(query_str)
RAG Use Cases: A Few Glimpses
RAG (Retrieval-Augmented Generation) models, especially when combined with large language models (LLMs) like GPT-3 or GPT-4, are poised to revolutionise numerous applications in NLP. Here are some compelling use cases for RAG LLMs:
1. Advanced Question Answering (QA):
- Clinical QAs: Medical professionals can extract insights from vast clinical literature to assist in diagnostics or treatments.
- Legal QAs: Quickly extract specific legal precedents or clauses from a broad database of legal documents.
2. Contextual Chatbots:
- Customer Support: Assist customers by fetching relevant data from a knowledge base in real time.
- Personalised Virtual Assistants: Fetch specific pieces of information from the user's data to provide context-aware responses.
3. Research and Data Mining:
- Literature Review: Help researchers identify relevant articles or excerpts from vast archives.
- Patent Searches: Help inventors and businesses find related patents quickly.
4. Content Creation and Editing:
- Content Recommendations: Suggest relevant articles, books, or media based on a user's query.
- Contextual Editing: Offer context-based suggestions or corrections when writing or editing articles.
5. Educational Tools:
- Smart Study Assistants: Answer specific questions from students by fetching relevant data from textbooks or lecture notes.
- Examination Systems: Generate questions and their answers based on a provided curriculum.
6. E-Commerce:
- Product QAs: Provide detailed answers about products by fetching data from product descriptions or user reviews.
- Shopping Assistants: Help users find products by asking detailed questions and retrieving relevant product listings.
7. Gaming:
- Narrative Games: Generate contextually appropriate dialogues and story elements based on game lore and player choices.
- Interactive Storytelling: Allow users to ask questions about the story's universe and get in-depth, lore-consistent answers.
8. Custom Search Engines:
- Semantic Search: Using natural language queries to fetch more relevant results rather than just keyword-based searches.
- Data Analytics: Extract specific data points or trends from vast datasets based on natural language queries.
These are just the tip of the iceberg when it comes to RAG LLM applications. As the models become more sophisticated and datasets grow, we can expect even broader and more innovative use cases in the near future! A true shape-shifter, RAG can morph according to domain and industry needs, leveraging internal data to produce responses that resonate and inform, simultaneously.
For members Only:
Step-by-Step Colab Notebook and Expert Settings Guide
🥂 Now, while reading about the magic of RAG LLMs is all well and good, actually conjuring up that magic with code is where many wizards find their wands snapping. Running the code can often feel like trying to tickle a dragon – tedious and, well, slightly terrifying. But fear not! I've got you covered with a step-by-step Colab Notebook to make this adventure as smooth as butterbeer.
Narotam Singh: Conceptualisation, Design & Digital Management
Dive in, and let's make some code magic together!